IRI@AGU: Focusing on Floods
Often considered one of the most revolutionary technologies for climate research, remote sensing has the capacity to vastly improve the predictive strength of a wide variety of forecasting methodologies. However, this is still a rapidly-growing field and continuing to evaluate and cross-reference remote sensing data against other data-gathering methods is necessary to improve accuracy, a topic IRI has written about in the past in regards to index insurance. As floods continue to be a challenge in places like Bangladesh, one of the six countries ACToday has focused on, it will continue to be necessary to improve remote sensing data collection in order to continue to improve the climate information resources farmers in those areas need to make decisions in coming seasons. Beth Tellman is a postdoctoral research scientist who studies flood risk and land use change. We asked her a few questions about the work she’s doing at IRI, which she’ll be presenting at AGU.
What are flood-sensing algorithms? How do they work? How do you improve the accuracy of these algorithms?
Flood sensing algorithms are equations designed to identify the signal of water on the land surface. Once this water signature can be identified mathematically, it can be detected in any pixel in satellite image to classify if that pixel is water or land. Every satellite has a unique water signal. In optical satellites, which operate sort of like a fancy camera that captures many intervals of the light spectrum, water tends to be very dark and easily separated from other objects. The land surface—even dark objects like roads or soils—tend to reflect some light in the near infrared or short-wave infrared spectrum. Other satellites are radar based—sending down active signals to earth and assessing the way the signal bounces back (often called backscatter). Water—a smooth object—tends to have a smoother signal (and lower backscatter) compared to other surfaces. So, flood detection algorithms essentially map surface water, and the analyst can then remove “permanent” water to separate the flood water from normal or seasonal surface water.
Improving algorithm accuracy for single-satellite sensors can be done by developing better mathematical techniques to separate water from land. This is typically done through better methods or better reference data (e.g points or maps of verified flood and non-flood areas) to fine tune or train algorithms. However, because of infrequent satellite revisit time and cloud interference, I argue that perfecting algorithms is unlikely to make better flood maps. The most gains can be made using data fusion—mapping floods across many types of sensors, or using other data from crowdsourcing or flood models—to fill in what the satellite cannot see.
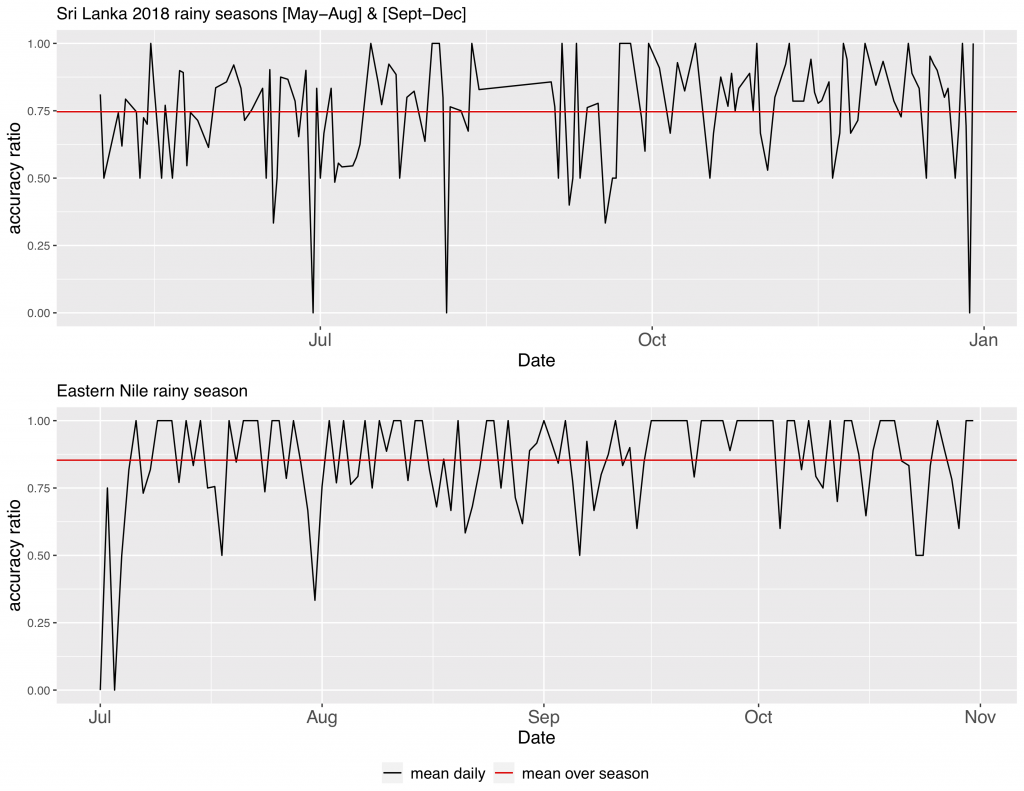
You’re relatively new at IRI, how do you see your specialty in remote-sensing fitting into existing work IRI has done on flood-vulnerable communities?
IRI has done a lot of work on climatic extremes for both droughts and floods, mostly looking at precipitation and soil moisture. My expertise can take these analyses one step further by linking observations of flood damage and inundated areas to climatic variability. Humans have built so many adaptions to floods, that heavy rainfall does not always mean a heavy flood if there is well-built infrastructure. Floods also tend to accumulate in marginalized communities who experience systematic inequality or who can’t afford—or aren’t afforded by their government—the necessary protection. Directly observing inundation provides data to dig deeper into these social questions that precipitation data alone cannot resolve.
I am using these data in applications for index-based insurance in Bangladesh as part of Columbia World Project’s Adapting Agriculture to Climate Today, for Tomorrow (ACToday).

In your abstract, you point out an accuracy gap between the published methods for making flood maps from satellites and many instances in which these methods are implemented across many images. Why do you think this gap is so large and how does the new metric you’re proposing help close it?
The gap is large because most accuracy and validation techniques rely on sampling many points or comparing a flood map to a high-resolution optical image. This method demands a relatively cloud-free optical image. Cloud-free images that capture flooding are rare because floods often occur due to heavy rainfall and storms that come with large clouds that block the view. This means that cloud-free images are available usually after the storm subsides, and flood water will only be present in a large watershed or a slow-moving event. Urban floods or floods of lower magnitude or high frequency are often not captured. Thus, algorithms tend to report high accuracies on slow-moving floods, which are easy to map.
Reproducing these same algorithms on fast-moving floods, in areas with many clouds and cloud shadows (which are dark and often misclassified as flood), or in more complex urban areas with infrastructure, tends to achieve lower-accuracy results.
I also think the sampling approaches accepted in published literature tend to be too generous towards correctly mapping land! Mapping flood waters—which are turbid and often mixed with vegetation—are much harder to map than surface water in a lake on a clear day. Most papers use one or several flood events to test an algorithm, instead of assessing how well an algorithm works consistently over time.
We need metrics that measure data coverage and algorithm accuracy targeted at the objects decision makers care about, which I call critical assets. Coverage and critical asset accuracy need to be assessed daily over an entire rainy season—ideally over multiple seasons.
Most algorithms mark cloud or cloud shadow areas as “no data”. This means that a flood map where 80% of the area is “no data” but the remaining 20% was accurate mapped at 95% is often reported as having 95% accuracy. But for a decisionmaker—is a map where 80% of the area is missing a flood map with 95% accuracy? Probably not. I think in flood mapping we need to report the data coverage metrics along with algorithm accuracy metrics—and calculate the unmapped area over time. Using a sensor that often has missing data due to clouds, even if the algorithm is 95% accurate, could be less preferrable to a decisionmaker (but depends on the decision!) than using a radar sensor (that can see through clouds), which has 100% coverage but an algorithm that is only 70% accurate. The accuracy-coverage tradeoffs need to be made clearer in remote sensing publications. The accuracy-coverage tradeoff may be different for disaster relief, insurance, or flood recover applications.
Why is it so important to continue to evaluate and improve the quality of information from satellites?
The frequency and magnitude of floods already causes setbacks to development especially in vulnerable communities – and is only expected to increase. Flood impacts are expected to double with 1.5 degrees of warming and could potentially quadruple with 3 degrees of warming—which is the track we are essentially headed on now!
Satellite-based flood maps can improve models that predict flooding and establish new forms of financial protection, like insurance, in new and cost-effective ways to protect and promote sustainable development. Satellite information can also provide greater access to flood maps in places that lack field instrumentation and need immediate information for response in emergencies. Investing in this technology is an investment in mitigating the damaging effects of floods and now and in the future.
You must be logged in to post a comment.