IRI Unveils Its New Generation of Climate Forecasts
Leer en castellano
This spring, IRI implemented a new methodology for our seasonal temperature and precipitation forecasts around the world. We asked Simon Mason, Andrew Robertson and Tony Barnston, three of our senior climate scientists who lead the development and tailoring of IRI’s forecasts, to answer some fundamental questions about the new forecast. If you use our forecasts and have further questions, or if you have feedback about the new forecasts, please send an email to info@iri.columbia.edu.
Why is there a new forecast?
Simon Mason: When the IRI started making forecasts in the 1990s it used climate models that represented only the atmosphere. More sophisticated models that included the oceans were available, but these models could not easily generate more than a short history of forecasts (called “hindcasts” — see sidebar) because of poor data availability for the oceans. We needed data from these hindcasts to cover a longer period of time to develop an accurate assessment of how well these models work and what corrections might be needed to produce a reliable forecast. Two decades on, these “coupled models” — the ones that include ocean and atmosphere — can now generate a sufficient history of hindcasts. The models have also undergone improvements, and are now routinely used in operations by most global forecasting centres, including NOAA’s North American Multi-Model Ensemble (NMME) project.
Climate Science Explained: Simon Mason on Hindcasts
When we make forecasts, by definition they are about the future. However, because the models we use to predict the future are imperfect, it is valuable to have many previous forecasts so we can see whether the models consistently predict too much rain, for example, and then make corrections.
When we get a new climate model we cannot afford to wait years and years until it has made lots of forecasts, so we make a pretend set of forecasts instead. For example, we pretend that it is May 1981 (or as far back into the past as possible), and without using any data after May 1981 we then make a forecast for the next few months. Next we pretend it is May 1982, and make another “forecast”, repeating this process right up until last year. These pretend “forecasts” are called “hindcasts”.
If we start too far back into the past then there may not be enough historical data to make a reasonable, comparable forecast, so we have to balance generating many hindcasts that extend far back into the past against generating a smaller number of hindcasts that will be of similar skill to the real forecasts that we wish to make.
Andrew Robertson: Until a few years ago, data from an ensemble of coupled forecast models were not easily and freely accessible in real time, both because of data policy restrictions at the various global forecasting centers, as well as the lack of coordinated data infrastructure to share the data. For the first time, NOAA’s NMME project has made real-time and hindcasts from up to nine coupled models from US institutions (NCEP, NASA, GFDL, NCAR, COLA/University of Miami) and Environment and Climate Change Canada freely available through the IRI Data Library. This makes it straightforward for us to now base our forecast on the output of these NMME models. And, due to funding decreases, IRI was no longer able to run the older atmospheric global climate models in-house as it previously could.
SM: While the IRI no longer has the funding to run climate models in-house, we are able to set up a fully automated forecasting system that takes advantage of the coupled model forecasts from the NMME project, as well as the two decades of experience IRI has in generating forecasts from such systems.
Has the method of creating the forecast changed, and would that affect how the forecast can or should be used?
SM: There are two categories of changes in the methodology of the new forecasts — we are using new climate models, and we are using new methods to turn those model outputs into reliable forecasts.
The new climate models represent the climate systems better than the old ones did, but the basic principles of how those models work are unchanged – or, if you prefer, the physical basis for making the seasonal forecasts remains the same. The new forecast methodology is designed to make corrections to the climate models based on their ability to predict previous years accurately. We are also producing information with more spatial detail than before.
In principle there should be no reason to change how or when the new forecasts are used, because in both the new methodology and in the old, the forecasts were made to be taken at face value – i.e., the probabilities are supposed to give a reliable indication of what the season will be like.
AR: For those who would like more information about our new methodology, we’ve put together a page here.
Can we make comparisons with old forecasts? For example comparing forecasts from moderate El Niño event years to this year’s forecast?
SM: To be clear, there has been no change in the El Niño and La Niña (or ENSO) forecast products, it is only our rainfall and temperature forecasts that have been modified. But, in terms of comparing the rainfall and temperature forecasts — as I mentioned in the earlier question about whether the forecast can still be used in the same way, the forecasts are meant to be taken at face value. So if this year the forecast indicates a stronger probability than in previous years, then that does reflect greater confidence.
But what we cannot conclude is that the impact is likely to be stronger. For example, if there is a 60% probability of above-normal rainfall during moderate El Nino conditions in our new system, and only a 50% probability during similar conditions with the old system, then we are indeed more confident that above-normal rainfall will occur; but it is invalid to conclude that we think there will be more rainfall than in previous years with moderate El Nino conditions.
Tony Barnston: It’s true that our ENSO forecast materials have not changed. But the ENSO forecasts (in fact, forecasts of the entire sea-surface temperature field) used in the process of making the climate forecasts have now changed, and likely for the better, since they are based on the eight or so state-of-the-art coupled models instead of on just three models, one of which was statistical and one of which was a simplified dynamical model that covered only the tropical Pacific Ocean. So, only one of the sea-surface temperature forecast models used to be state-of-the-art, while now all of them are.
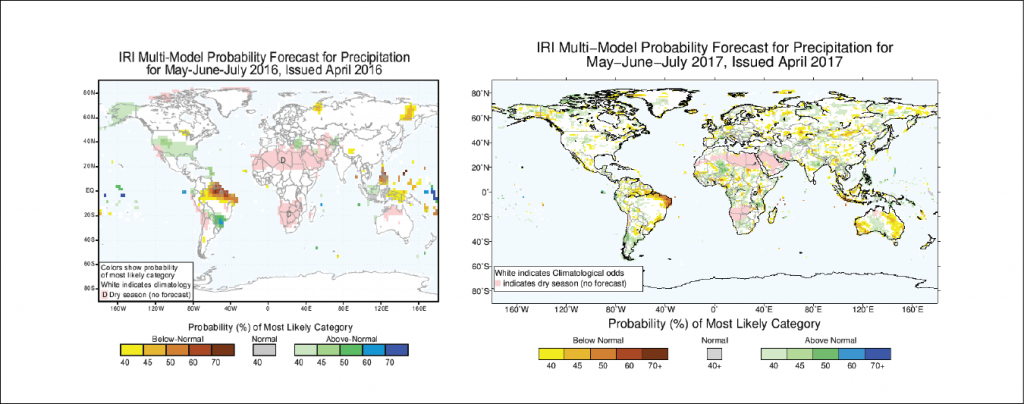
Side-by-side comparison of IRI’s old (left) and new (right) seasonal climate forecast for precipitation. Note that the forecasts do not show the same time period.
Why does the forecast look different?
AR: The new models run at a higher spatial resolution. They are at about 1-degree latitude-longitude resolution (i.e. about 100km), compared to about 2.8 degrees for the old ones (i.e. about 300 km), so we are providing the forecasts at 1-degree resolution, compared to 2.5 degrees before.
What are the implications of the higher resolution for a user?
AR: The improved resolution may or may not translate into more skill on smaller scales. We have noticed that the forecast maps sometimes look noisier at small scale, and the user should be aware of it. We are looking into improving our post-processing calibration method to reduce the noise.
Does this affect any IRI products other than the standard, tercile-based seasonal forecasts?
SM: Yes. The new forecast methodology feeds into some of our rainfall and temperature forecast products. These include the seasonal forecasts in the IFRC Maproom and the Flexible Forecast Maproom.
Is it more accurate than the old forecast?
AR: The answer to this question is not as simple as it may sound. There are many measures of forecast skill, and the old and new systems are different which makes them difficult to compare directly. We expect the new system to be at least as good because it is based on a newer generation of models and forecast initialization methods. We are in the process of fully verifying the new system to provide as full an answer to this question as possible.
TB: With the exception of the above-normal temperatures, the new forecast output has more areas that are not the climatology forecast (i.e., more colored areas on the maps; the models “have more to say”) than the old forecast output, and this greater sensitivity presumably reflects higher accuracy, but confirmation of this will come with our verification now in progress. With regard to the probabilities for above-normal temperature, we’re investigating whether the new forecasts underestimate the tilt toward above-normal due to the models’ possibly inadequate sensitivity to CO2 increases.
As you were developing the new forecasts, did needs/input from users play a role?
SM: The most important and the most difficult question!
There are many reasons why IRI started making seasonal forecasts in the late 1990s. In part it was a response to the 1997/98 El Niño, which was expected to have major impacts around the globe. Although that is only 20 years ago, there were very few countries and centers producing seasonal forecast information at that time – which perhaps shows how far we have come in the last two decades. At that stage the climate community had a very poor awareness of potential users of seasonal forecasts, but we could at least advise many of the national meteorological services, which may have their own communication channels. So, during the late-1990s and early 2000s our main dissemination channel was to attempt to inform governments via these meteorological services. In addition, as countries and regional and global climate centers started to produce their own forecasts we wanted to provide a good example that could be emulated and adapted as appropriate.
However, as the IRI’s Applications Research Division (as it was then called) and the broader climate service community began to develop experience in identifying and working with user communities, our forecasts have become of interest to an expanding range of users. In some cases we have worked directly with such communities to co-develop tailored seasonal forecast information. This tailored information is presented in custom-designed Maprooms, examples of which include those for the International Federation of the Red Cross and Red Crescent Societies (IFRC) and the World Food Program (WFP).
When the new forecasts were redesigned, we took into account inputs from some of our main partners, such as the IFRC and WFP, and also from some of the many Meteorological Services around the world that consult our products. Of course, everybody has been requesting higher levels of certainty in the forecasts (which translates to more and deeper colours on the maps), and using the state-of-the-science climate models should help with that objective. Many users have also been requesting more detailed spatial information, which we have addressed in the new forecast too, although for some applications – especially those concerned with flooding – less spatial information may provide better quality information. In such cases, forecast tailoring is required – the development of customized products such as those in some of our Maprooms. We hope to work with our partners and other potential users to explore what works best for them.
Each time we make a forecast we do not think about how specific users will respond to the information. In fact, it is important not to, because otherwise we end up hedging the forecast. It is important for the forecaster to communicate what (s)he thinks will happen, rather than thinking about how to affect the users’ responses. Holding such a detached attitude, however, is a very different question to that of how to communicate a forecast so that it facilitates users’ decisions. That interaction is important for ensuring that the forecast is clearly understood and provides relevant information.
You must be logged in to post a comment.